ChatGPT:你的助手,还是你的敌人?
文章主题:ChatGPT, 自回归, 因果掩码, 概率模型
ChatGPT自从2022年底发布以来引起了很大反响,子弹已经飞了两个月了,今天重新整理一下ChatGPT以及个人的一些理解。
TL;DR: ChatGPT的内核是InstructGPT[1]。随着language model(LM)越做越大,InstructGPT的作者们发现这些LMs其实经常和用户的意图不完全一致/对齐,这引发作者们的思考:如何得到能与用户意图更一致的LM?于是InstructGPT横空出世,其目标是“Align language models to humans”,具体的对齐方法采用Reinforcement Learning from Human Feedback(RLHF)[2]。简单说就是在训练LM时要“human in the loop”,用人类的示例/评价/比较等反馈信号调整LM,让LM输出的结果往人类意图方向靠拢。
个人ChatGPT体验报告
ChatGPT在哪些地方帮到我了?
有些中文文档需要很官方的文书表达(比如基金申请书),通过巧妙的提问可以让ChatGPT输出很多思路甚至有些可以直接拿来用;帮助我快速了解一个大的领域,虽然看不太准,但是也提供了一点借鉴。ChatGPT技术上还存在哪些缺陷?
ChatGPT经常一本正经地胡说八道;ChatGPT经常很啰嗦;ChatGPT给出的信息我经常需要用Google double check;ChatGPT每次输出的结果“不一致”(本质原因是因为它是概率模型,每次采样的结果都不一样)。Background

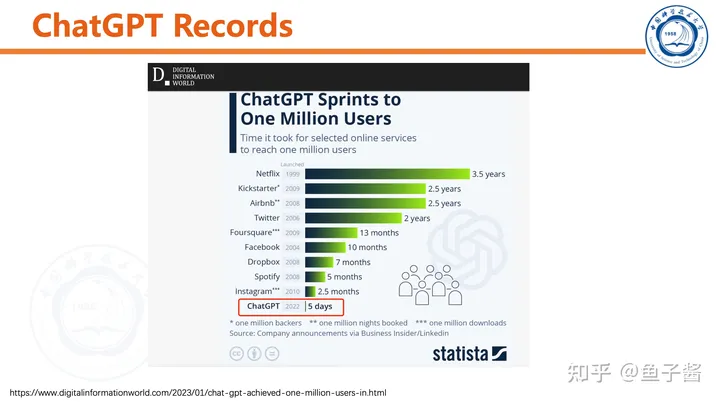

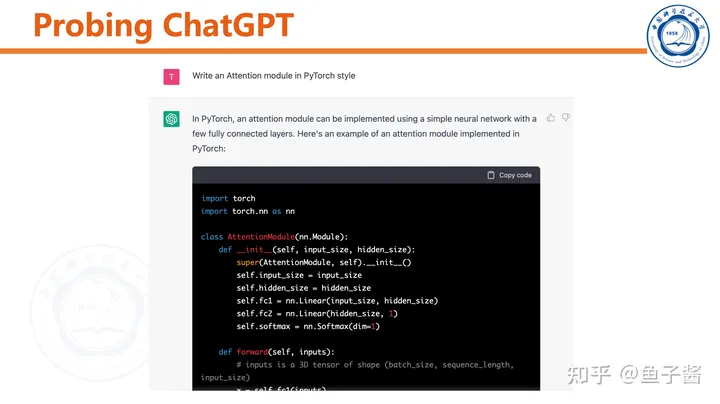
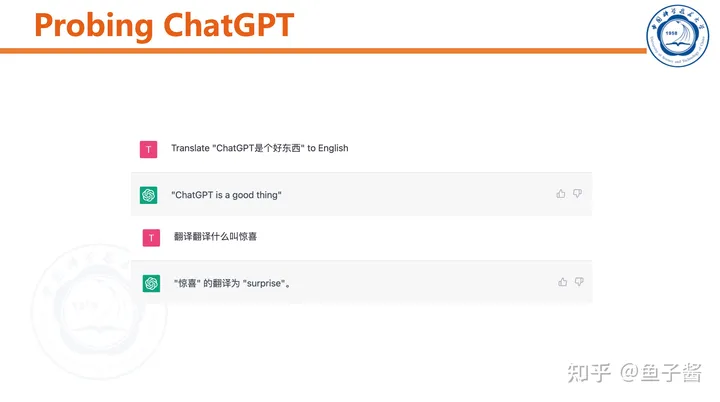
我首先对ChatGPT做了简单的测试,直观感受一下。
ChatGPT可以和用户“chat”,能根据聊天历史调整输出。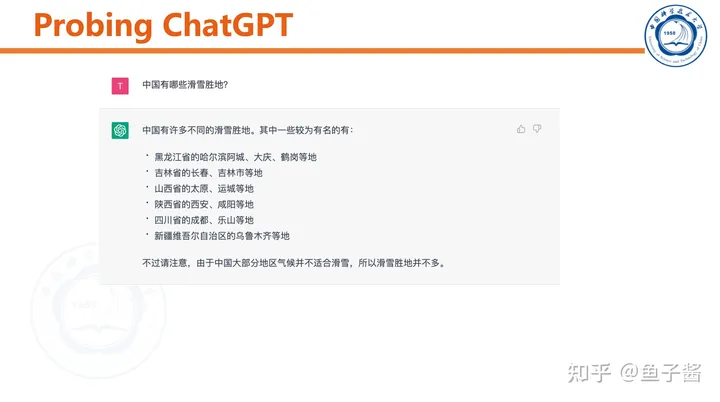
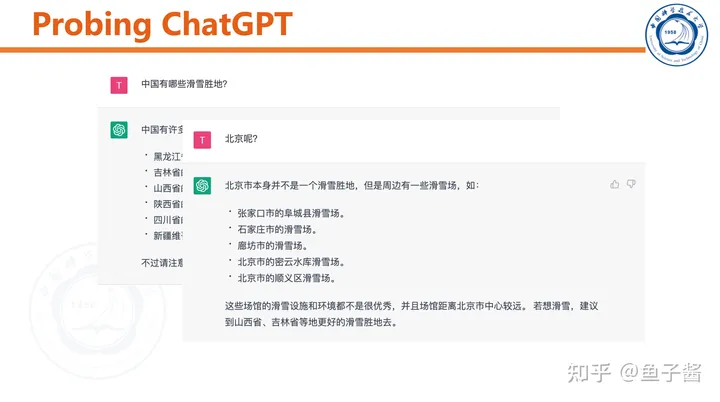


InstructGPT
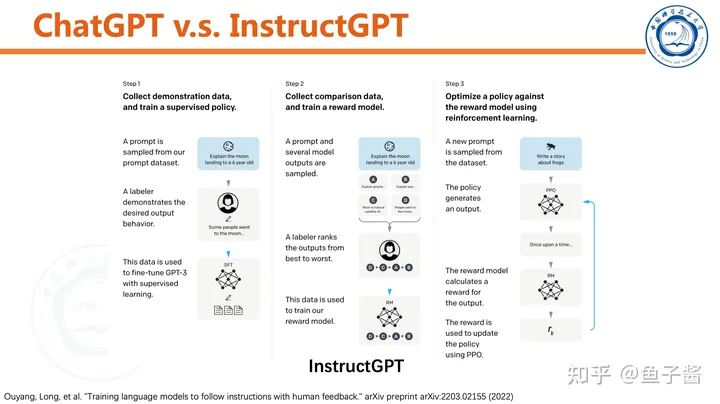
对比一下ChatGPT和InstructGPT,方法几乎一模一样。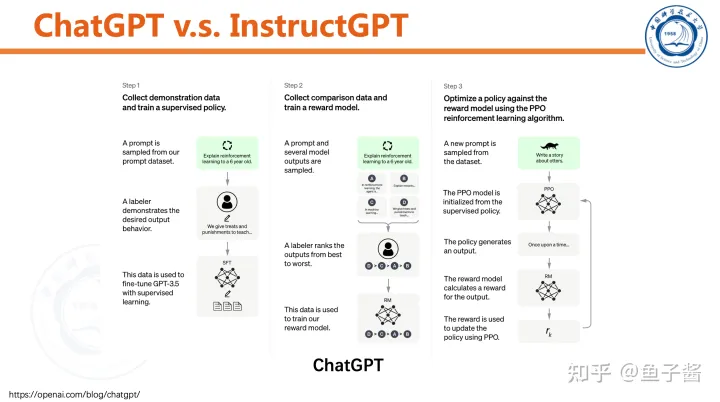

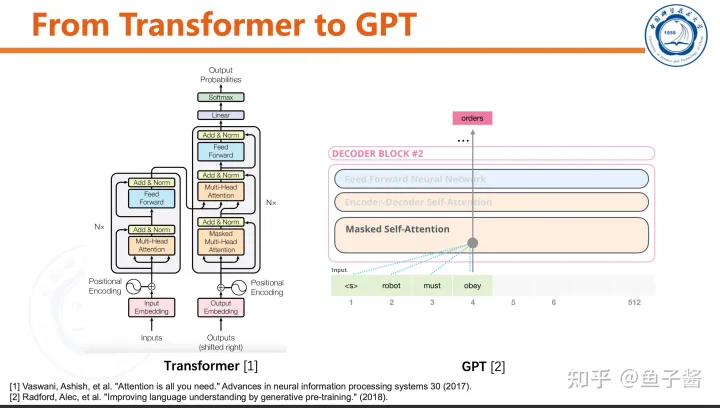
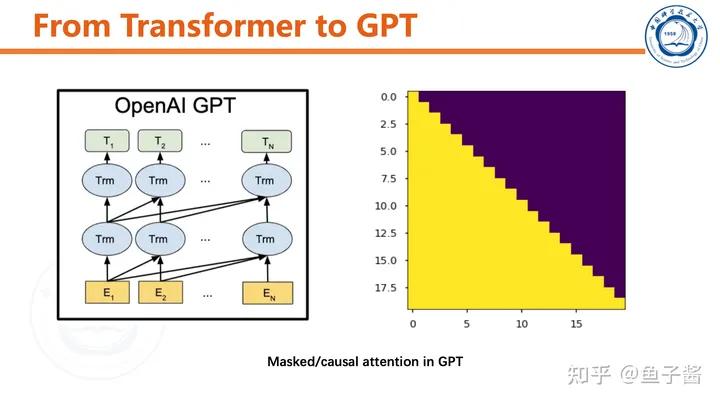
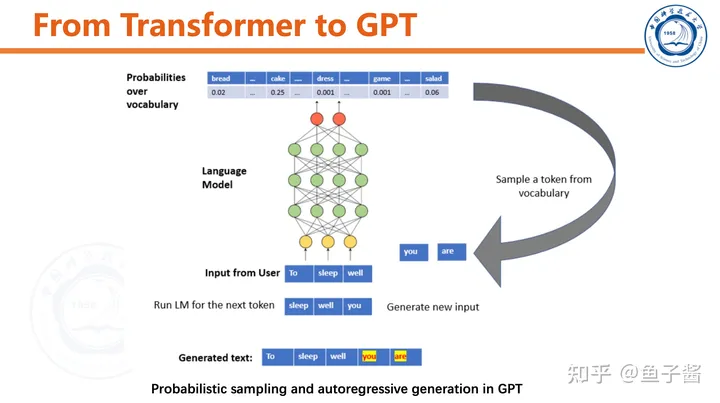
🎉 GPT Model Introduction 🎉Hey there! Are you interested in learning more about the Transformer Decoder, a powerful component of the GPT model? Well, you’ve come to the right place!The Transformer Decoder is a key part of the GPT architecture that enables it to generate text based on input prompts. It’s responsible for processing and generating sequences of tokens, which are the building blocks of natural language.💡 Key Features 📝1️⃣ **Transformer Encoder**: The Transformer Encoder is the first component in the model that processes the input prompt and generates a sequence of hidden states. These hidden states are then passed to the Decoder for further processing.2️⃣ **Transformer Decoder**: The Transformer Decoder is responsible for generating text based on the hidden states generated by the Encoder. It uses a self-attention mechanism to weigh the importance of different tokens in the input sequence, and generates output tokens one at a time.3️⃣ **Self-Attention Mechanism**: This mechanism allows the model to focus on specific parts of the input sequence when generating output tokens. It enables the model to understand the context of each token and generate more coherent and meaningful text.4️⃣ **Causal Masking**: The Transformer Decoder uses a causal mask to prevent the model from attending to future tokens in the input sequence while generating output tokens. This helps ensure that the generated text is not influenced by any information beyond the current prompt.5️⃣ **Probability Model**: Finally, the Transformer Decoder includes a probability model that generates probabilities for each token in the output sequence. These probabilities can be used to generate more diverse and interesting text by sampling from them.💡 Benefits 📝1️⃣ **Generative Power**: The Transformer Decoder enables the GPT model to generate text based on input prompts, making it a powerful tool for natural language processing tasks such as language translation, summarization, and generation.2️⃣ **Contextual Understanding**: The self-attention mechanism in the Transformer Decoder allows the model to understand the context of each token in the input sequence, enabling it to generate more coherent and meaningful text.3️⃣ **Diverse Outputs**: The probability model in the Transformer Decoder enables the model to generate diverse and interesting outputs by sampling from them.4️⃣ **Efficient Processing**: The Transformer Decoder is designed to be efficient, making it suitable for use on a wide range of devices with limited processing power.In conclusion, the Transformer Decoder is an essential component of the GPT model that enables it to generate text based on input prompts. Its key features, such as self-attention, causal masking, and probability modeling, make it a powerful tool for natural language processing tasks. So why not give it a try and see what kind of amazing results you can achieve?

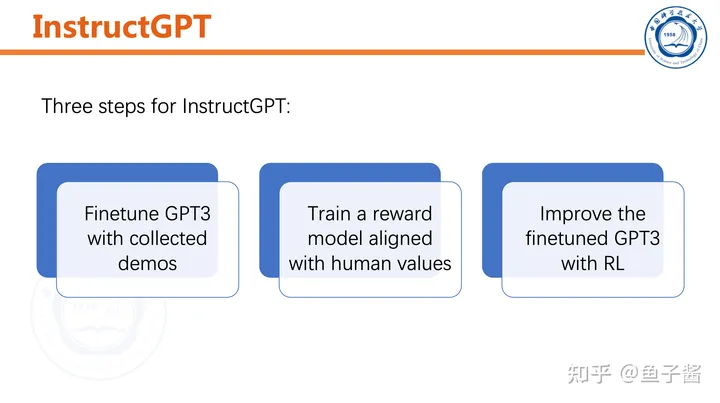
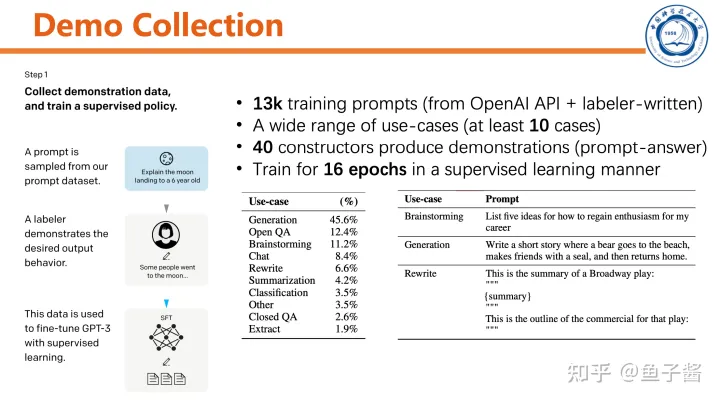
# InstructGPT的第一步:采集人类标注的demo## 任务介绍在本文中,我们将探讨如何使用InstructGPT进行自然语言处理任务。首先,我们需要明确的是,InstructGPT是一种基于预训练模型的监督式finetune方法。这意味着我们首先需要收集一些人类标注的示例数据,然后使用这些数据来训练我们的模型。## 数据采集在开始训练之前,我们需要收集一些人类标注的示例数据。这些数据可以来自各种来源,例如文本、语音或图像。然而,最重要的是确保这些数据的质量和多样性。高质量的数据可以帮助我们更好地理解自然语言,并提高我们的模型性能。## 训练过程一旦我们有了足够的数据,就可以开始训练InstructGPT了。首先,我们需要将数据加载到我们的模型中。然后,我们可以使用监督式finetune方法来调整模型的参数,使其能够更好地理解和生成人类语言。## 结论总的来说,InstructGPT是一种强大的自然语言处理工具,它可以帮助我们解决各种自然语言处理任务。然而,要充分利用它的潜力,我们需要收集高质量的数据,并使用适当的训练方法。

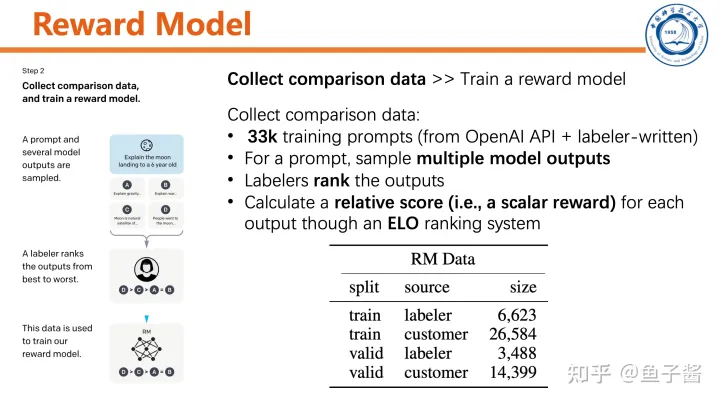
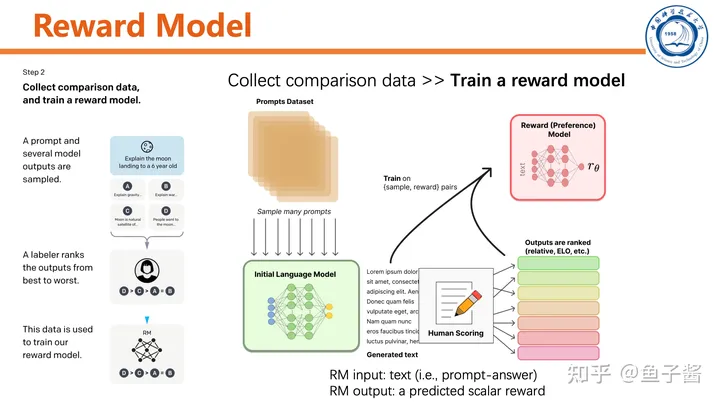
第二步,训练reward model。
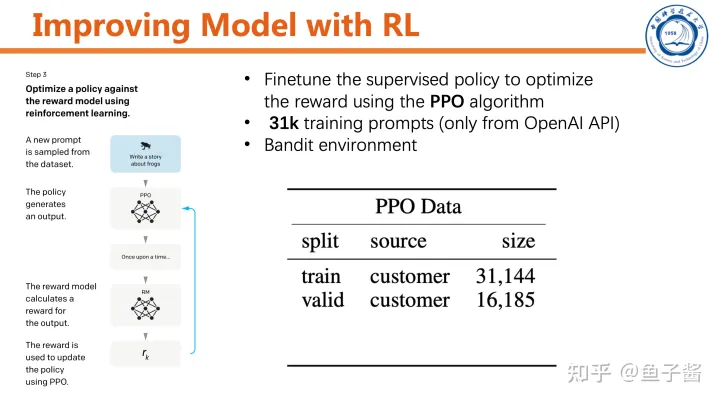
最后一步,用RL提升SFT model。
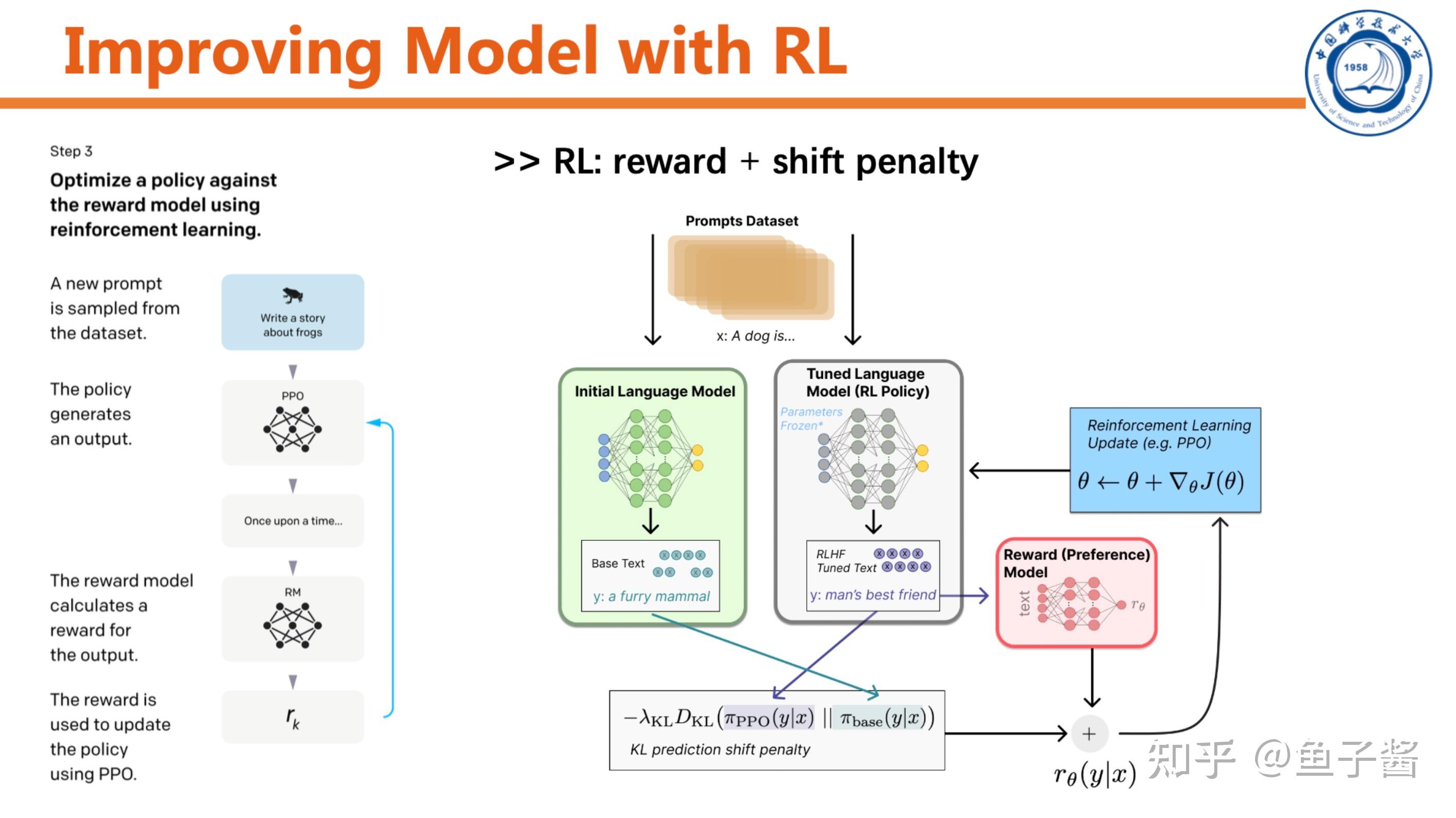
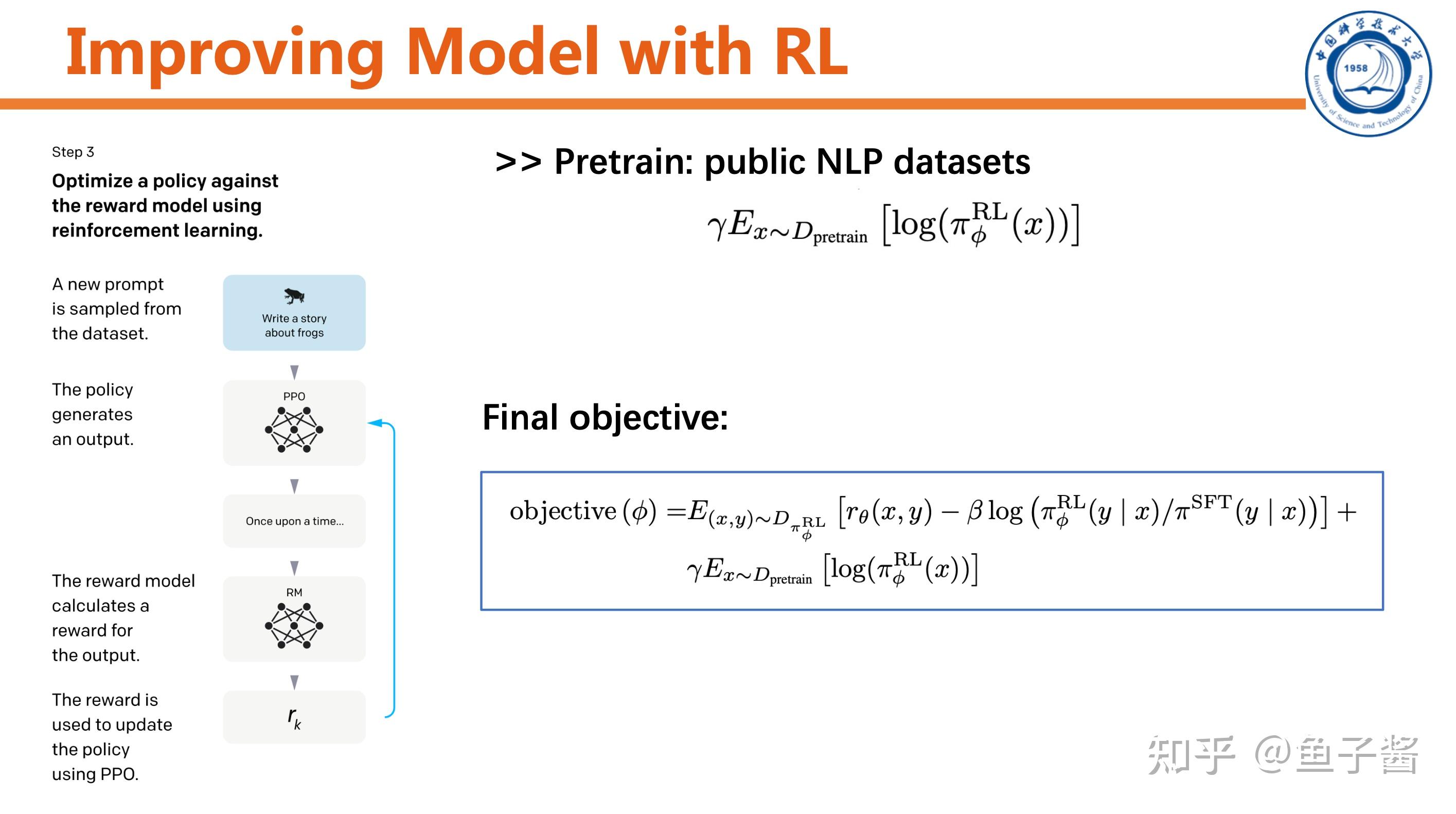
Experiment

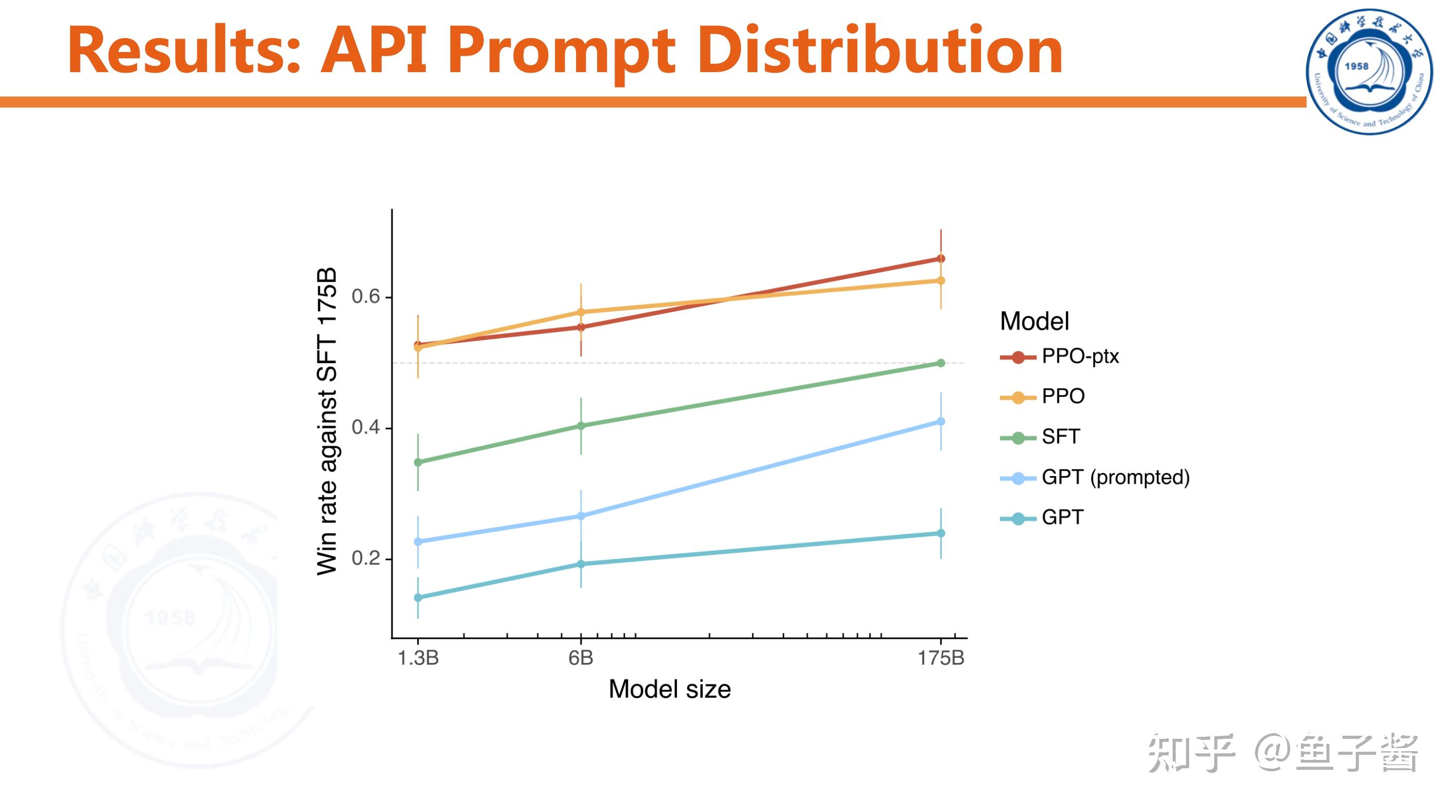
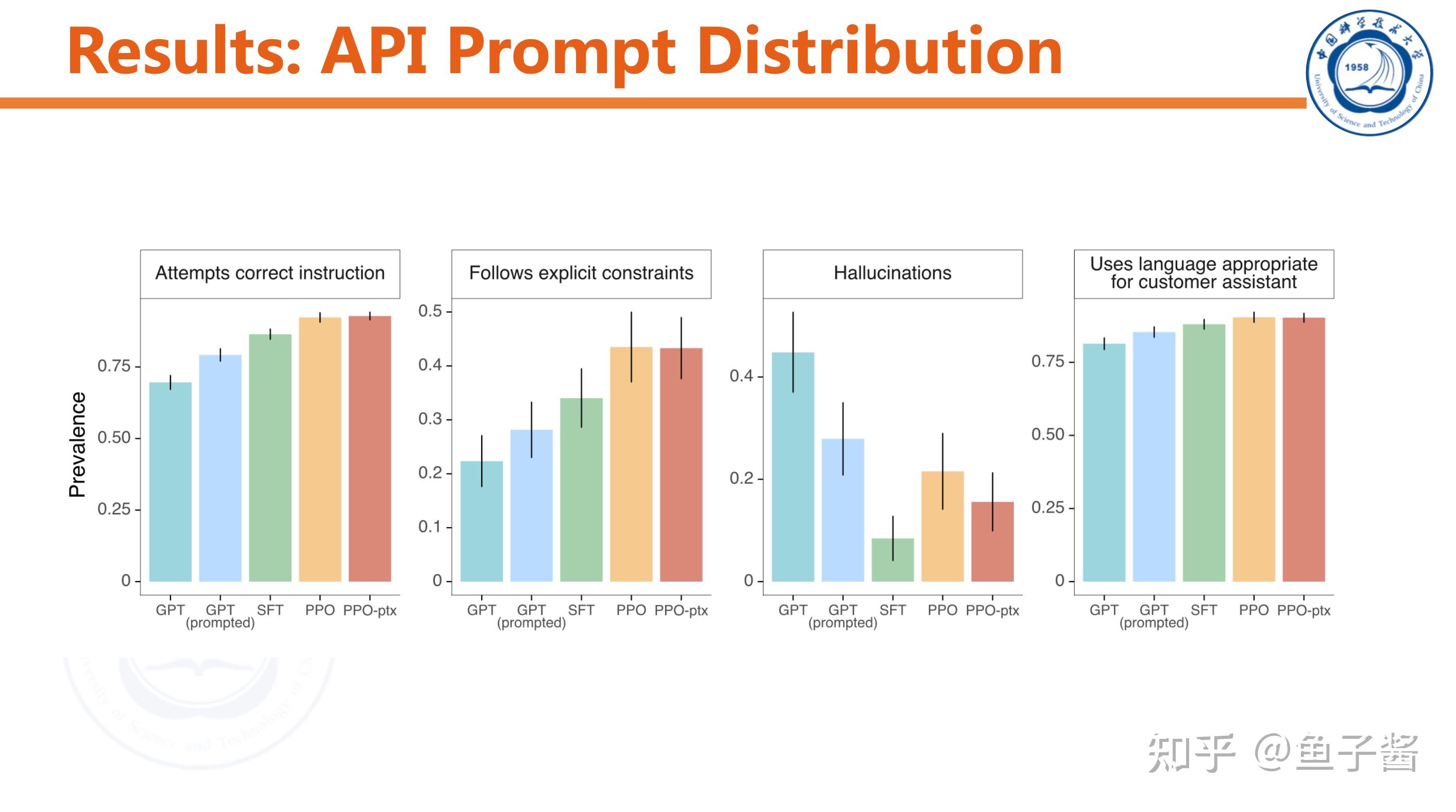

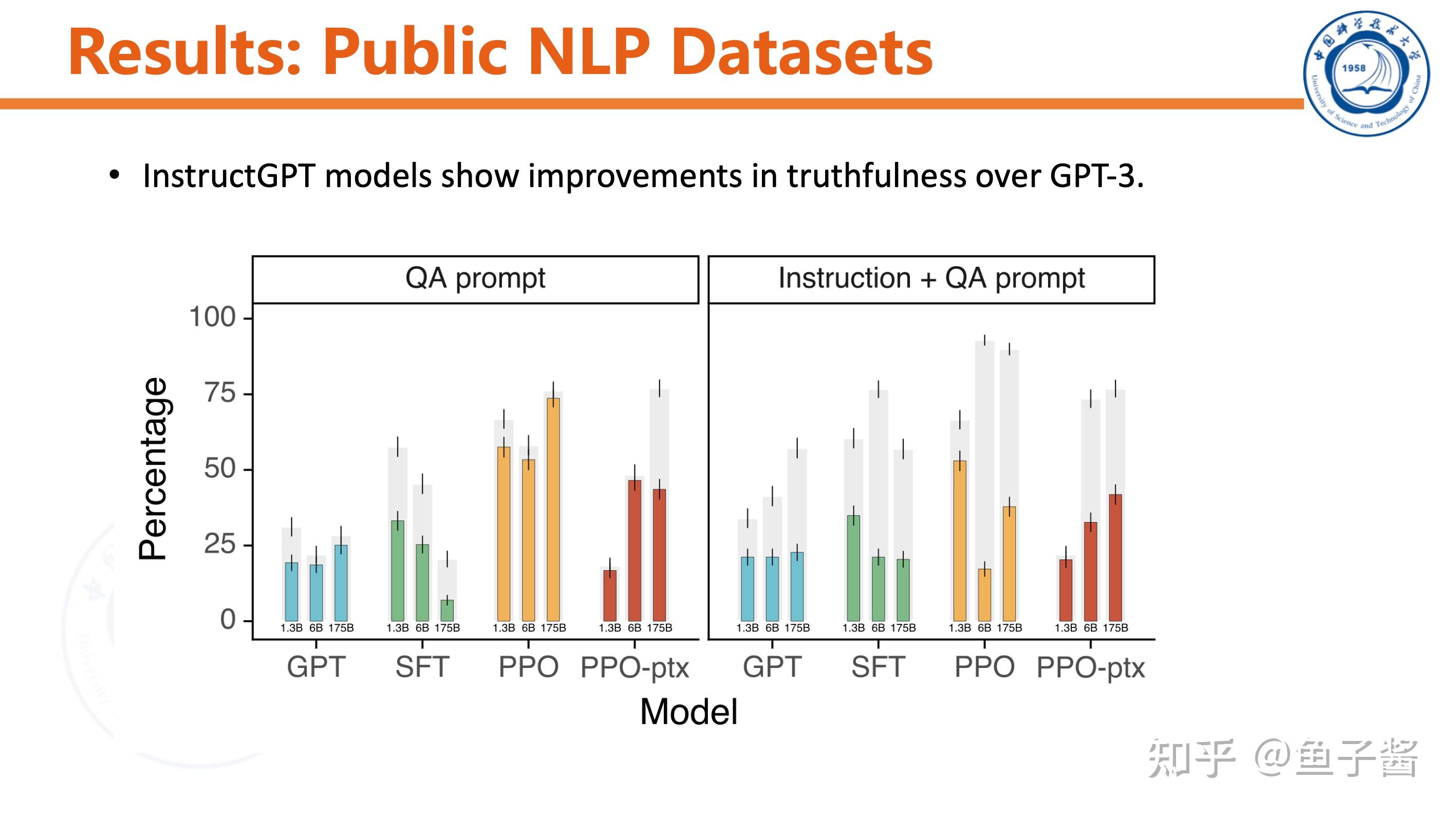





Discussion



🎉 DeepMind的工作总让人觉得很聪明和新颖,而OpenAI的工作则总能给人带来实际的帮助(有时候甚至会有些粗鲁,但又不失“大手笔”的感觉)。阅读这两个机构的研究论文总是令人感到愉快。
参考
^Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C.L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A. and Schulman, J., 2022. Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155. https://cdn.openai.com/papers/Training_language_models_to_follow_instructions_with_human_feedback.pdf^Reinforcement learning from human feedback(RLHF) https://huggingface.co/blog/rlhf
AI时代,掌握AI大模型第一手资讯!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
扫码右边公众号,驾驭AI生产力!